This is the second installment of a 3-part series on machine learning. If you want to read the first part, the link is below. The outline of the 3 installments is:
- Machine Learning Introduction
- Various implementations of machine learning
- Impact to business of machine learning computers
The last installment will be published in the next few weeks. I will update this article with a link to it.
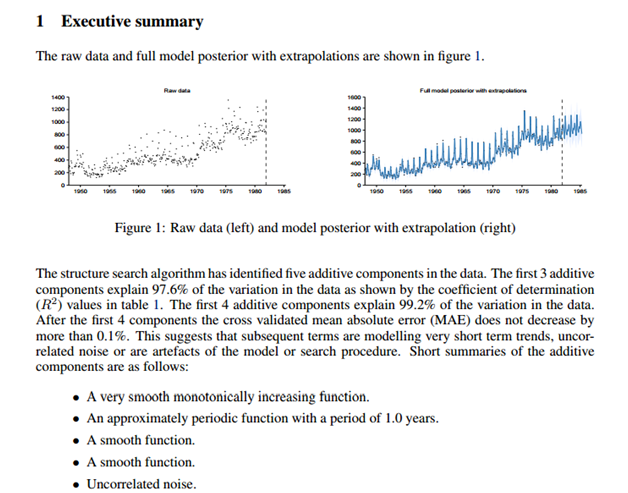
In the last post, we outlined the basic underpinnings of Machine Learning in the context of Big Data. Here we shall examine some implementations of Machine Learning, a discipline that stemmed from research into Artificial Intelligence (AI), especially concerning algorithms that learn from the data autonomously. In this post, let’s look at some AI machines programmed to perform machine learning, and their fascinating results and occasionally surprising side-effects. Although the focus is on machine learning, the mechanics themselves belong to a broader context of AI.
Deep Blue
On February 10, 1996, a computer called Deep Blue beat a human at a game of chess. What was historic about this was the fact that the human was the reigning world chess champion, Gary Kasparov. Although, eventually Kasparov went on the beat the computer, it was the beginning of the end of human dominance in this extremely strategy-based board game.
Then in May 1997, the same computer after several upgrades played Kasparov again. This time the computer beat Kasparov 2-1 in a 6-game tournament. If there was any debate that a computer cannot beat the best human in a game of chess, this put an end to it. Or did it?
Deep blue is just as fascinating in what it is not, as much as in what it is. While, technically, Deep Blue’s deep knowledge of chess came from learning prior games, its super-power truly lies in its massive processing capacity. Deep Blue is a massively parallel system (technical term for a lot of processors, running in parallel), with 30 processors plus 480 chess chips. In simple English, it’s a beast. It can process nearly 300 million positions/moves per second.
That raises a question: Is Deep Blue really a learning machine? Firstly, according to the rules of the tournament, Deep Blue’s developers were allowed to alter/upgrade the software between games. This means that Deep Blue’s engineers were learning the game and teaching it to the computer, rather than the computer doing it for itself. But IBM chalks it up to upgrading the system’s learning mechanism. Fair enough.
Compare deep blue’s functioning to how a human thinks. A human gets better and better at playing chess as they play more and against better opponents. Even if IBM engineers were right in that their inter-game intervention was only upgrading, the question still is: Does deep blue understand the game of chess and its strategies the same way a human learns. I am not referring to the wetware [http://en.wikipedia.org/wiki/Wetware_%28brain%29] vs hardware/software argument. Humans obviously are not processing more than 200 million moves per second: far from it. Deep blue, on the other hand, does have this capability and uses it quite effectively. This clearly points to the difference in human insight and the brute force a computer. Deep Blue may or may not have had the same insight Kasparov had, but at the end of the day, Deep Blue won.

Source: Encyclopaedia Brittanica
Watson
For our second example of an artificially intelligent computer, we go back to IBM.
In 2011, Watson played Jeopardy! (a popular TV quiz show) with Brad Rutter and Ken Jennings, former winners of the game show. Brad Rutter never lost Jeopardy to a human opponent. Ken Jennings, of course, holds the record for the longest winning streak in Jeopady history, 73 in total. Together, these two men had walked away with more than $5 million dollars, when they played against Watson. In a 3 day tournament, Rutter and Jennings went head-to-head against Watson, only to see Watson trounce them in the end.
While crunching numbers is something computers are very good at, language processing has been a very challenging problem in computer science. IBM set out to take this challenge up, when they designed and built a computer named Watson. More specifically, Watson was exclusively designed to answer trivia questions asked in natural language.
Watson’s first task is to extract meaning from a vast database of documents, ranging from encyclopedias, news articles and literary works – millions of them. Keep in mind that this is not the same as Google’s search engine indexing the Internet. Document searching (and page ranking) is to take a keyword as query and return a list of documents that are relevant to the query. While a search engine knows the words in the indexed documents, Watson is supposed to understand the contents of the documents.
Understanding Human language is a difficult task for a computer, which thrives in a world of discrete numerical constructs. Real language is full of implicit and ambiguous references, whose meaning can only be extracted within the context of the conversation. Take for instance this phrase: “I like tea, but Java is what gets me going.” An average English speaker has no problem understanding that Java is a reference to coffee. We will be hard-pressed to find people who would mistake this java for either the computer programming language or one of the main islands in Indonesia. For a computer, on the other hand, this is a very difficult task – determining meaning by context. A compute trying to understand a phrase like “Here I am sitting in my hotel room in Java, sipping on my Java, and coding away in Java” would probably lead to a blue-screen-of-death [http://en.wikipedia.org/wiki/Blue_Screen_of_Death].
Let’s take look at how Watson discovers the right answer to a given question. Just like Deep Blue, Watson is a massively parallel computer: one built with a cluster of 90 IBM Power 750 servers, each one powered by an 8-core processor. All added up, Watson had 2,880 POWER7 processor cores and 16 tBs of RAM. Watson ran on SUSE Linux Enterprise Server OS using Apache Hadoop’s distributed computing framework.
On this infrastructure, Watson ran IBM’s DeepQA software, a software designed to run on massively parallel infrastructure. The mechanism with which this computer turned trivia questions is as impressive as the hardware and software it ran on.
Watson firstly, accumulated a vast amount of knowledge by storing and indexing millions of documents. When Watson received a question, it would first perform a task called “Question decomposition,” where it would break down and parse the question/clue into keywords and phrasal fragments. It would then run several natural language analysis algorithms on the decomposed question phrases, all in parallel. The more algorithms that return with the same answer, the more confident Watson becomes of that answer. These two steps were “hypothesis generation” and “evidence scoring.” Based on this scoring, Watson would then rank the hypotheses. Together, score and rank, helped Watson determines the “confidence” it had in the answer. When the confidence is high enough, Watson would buzz the answer.
Jennings and several experts in the field of neuroscience and artificial intelligence are convinced that this is very similar to how a human brain works, under the same circumstances.
Answering Trivia might sound trivial, but the implications of Watson are far-reaching. From then on, Watson went on to do some serious work around the world. You can read more about it here
http://www.forbes.com/sites/bruceupbin/2013/02/08/ibms-watson-gets-its-first-piece-of-business-in-healthcare/
The final scores of the Jeopardy! game was:
- Rutter: $21,600
- Jennings: $24,000
- Watson: $77,147
Ken Jennings, in his final jeopardy question, wrote underneath his answer: “I for one welcome our new computer overloads.”

Source: New York Times
Other examples
While doing research for this article, I came across several fascinating examples of machine learning and artificial intelligence. In the interest of keeping this article short, I have not included them. If you’re interested in hearing more fascinating stories like these, please leave a comment at the end of this post. If there is enough interest, I will put them together in a separate post.
We are seeing a technological revolution, one that began at the turn of the century. In the past, though, technology replaced manual labor and work that involved a high degree of calculation. But recently we are seeing great progress made in domains which were previously thought to be exclusively human domain – thinking, learning, and strategizing. Increasingly this new computing paradigm seems to be encroaching and infringing upon our prized abilities. From the 19th century till the end of the 20th century we saw robotics replacing jobs that required manual labor. But the current trend is of replacing mid- and high-skilled workers. The computer that beat us at chess and trivia pave a path for the computers that will replace business strategists, scientists, doctors. Creativity will soon be replaced by algorithms for creativity.
There are social implications that we need to be concerned about, apart from the economic benefits of these. In the next post (the 3rd installment of this series), we will examine exactly these : the economic and social implications of the new wave of learning machines.