This is the third and last installment of a 3-part series on machine learning. If you want to read the first two parts, follow the links below. The outline of the 3 installments is:
- Machine Learning Introduction
- Various implementations of machine learning
- Impact to business of machine learning computers
In the last two posts, we explored the idea of Machine Learning and its application. This post will be about how learning machines, and computers in general, impact and influence businesses and vice versa.
Humans and machine have had symbiotic relationships. While humans shape machines, the irony is that machines have shaped humans just as much as, if not more. I don’t mean it literally, but machines may be seen to have influenced human progress in the political, social and most importantly economic systems to their current state of the art. Science and technology has been the center-stage of philosophical discourse in the Western hemisphere for more than three centuries. And computers have been the engine behind the economic success of the past few decades.
While it may be argued that the era of machines began either with the start of the Industrial age, or later at the Machine age, in the context of this post it really didn’t begin until the 1890 US Census. Herman Hollerith’s punched cards and the tabulating machine essentially cut down the census time from 8 years to 1 year.
“[Hollerith’s] system made it possible for one Census Bureau employee to compute each day the data on thousands of people, keypunching information that had been captured by tens of thousands of census takers.”
Library of Congress
http://memory.loc.gov/cgi-bin/query/r?ammem/mcc:@field(DOCID+@lit(mcc/023))
If a rudimentary computer by today’s standards can shave off 7 years, then imagine the time-savings today’s computers can provide. Of course, this tremendous positive impact is not without its negatives. This automated system measurably replaced thousands of Census Bureau employees overnight.
Since then, there has been a steady employment of computing machines replacing humans. After the end of the Second World War, ENIAC and UNIVAC paved the path for electronic computers to dominate business computation.
The business of running business has been transformed by newer and more powerful electronic computers. Again, as in the US Census case, while the economic sector has reaped the benefits the labor market saw the most negative disruption in this new world.
In the first wave of these computers, the world saw the low-skilled jobs vanish. Jobs that required repetitive tasks, especially ones that involve computations on large sets of numeric data, were slowly transitioned to automation. People holding jobs that can be described as routine and codifiable were the first to see the door. While in the early part of the 20th century, the job market was dominated by low-skilled workers, a constant decline in this class of jobs can be directly attributable to computers.
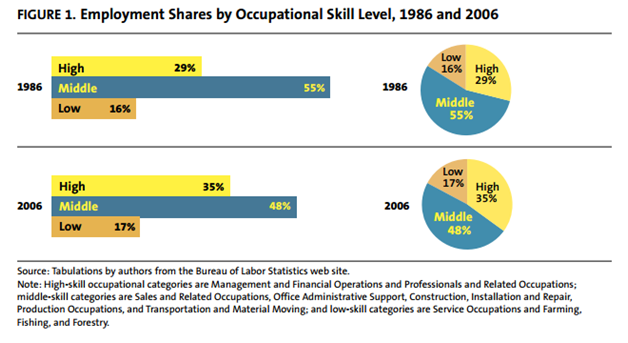
However, another trend that has caught the eye of the economists and policy makers is called the Polarization of the job market. Wikipedia describes it as “when middle-class jobs—requiring a moderate level of skills, like autoworkers’ jobs—appear to disappear relative to those at the bottom, requiring few skills, and those at the top, requiring greater skill levels.” As this chart depicts (by Harry Holzer and Robert Lerman [http://www.urban.org/UploadedPDF/411633_forgottenjobs.pdf]), while there has been a modest (and insignificant) growth in low-skilled jobs, there has been a constant decline in mid-level jobs – from 55% of all jobs in 1986 to 48% in 2006. What is notable is that the loss in mid-level skills is mostly offset by growth in high-skilled jobs.
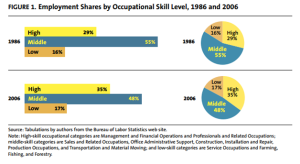
http://www.urban.org/UploadedPDF/411633_forgottenjobs.pdf
It is clear that technology and automation has caused a good deal of increase in wealth and prosperity. However, economists such as Joseph Stiglitz and Thomas Picketty have eloquently and persuasively argued that the problem is that the gain in wealth is concentrated in a relatively small number of participants in the economic system. Drawing from the experiences from the past, a policy dedicated to public and private investment in education and specialized skills training to the impacted masses is advised.
Having stated that the threat to low-skilled and mid-skilled labor categories is imminent, it seems to me that there is complacency on the high-skilled labor category. The general consensus is that high-skilled jobs will continue its strong growth. While I don’t argue that this consensus is wrong, one should, however, employ caution in prophesies such as these. Computers are increasingly doing tasks that had once been deemed impossible to be automated. Let’s take a look at some examples, where smart machines are doing high-skilled jobs.
Robojournalism
A surprising amount of what we read in newspapers and journals are actually written by computers with no human aid. Robojournalism was brought to people’s attention by “Quakebot”, a program written by Ken Schwencke. Quakebot wrote the first news article about the Mar-2014 earthquake off the Pacific Coast. This was not the first time a computer was employed to write news posts. But since then, robojournalism has gained momentum. Soon after, Associated Press announced that “the majority of U.S. corporate earnings stories for our business news report will eventually be produced using automation technology.” AP and Yahoo use a program called Wordsmith, developed by Automated Insights.
A particularly interesting case study is that of a Chicago-based company called Narrative Science They developed a piece of software called “Quill”, and similar to the earlier examples, this is a Natural Language Generator (NLG) platform that can process data, mostly in numerical format, and convert it into perfectly written narratives to be consumed by humans. Narrative Science started off by commercializing a research project at Northwestern University. It was first adopted to be used by sports channels and websites to report headlines for baseball games. It did so just by looking at the numbers. Take a look at this text that Quill generated:
Tuesday was a great day for W. Roberts, as the junior pitcher threw a perfect game to carry Virginia to a 2-0 victory over George Washington at Davenport Field.
Twenty-seven Colonials came to the plate and the Virginia pitcher vanquished them all, pitching a perfect game. He struck out 10 batters while recording his momentous feat. Roberts got Ryan Thomas to ground out for the final out of the game.
http://deadspin.com/5787397/we-heard-from-the-robot-and-it-wrote-a-better-story-about-that-perfect-game
This is an excerpt straight from Quill – no human literary intervention. This is just by parsing the box score of the game.
Narrative Science has taken this to the market to have their software write narratives for financial reports, etc.
Automatic Statistician
Big Data has generated a renewed interest in data analysis, especially applying statistical concepts to data in order to derive insights and meaning from large swaths of raw data. People calling themselves data scientists are popping up everywhere. Their main job is to take a deep look at the data (perform statistical analysis and modeling on it) and identify patterns and insights in it. These patterns and insights are valuable in predictive analytics as well as operations research. Automatic Statistician is purportedly in the business of automating this process of discovery.
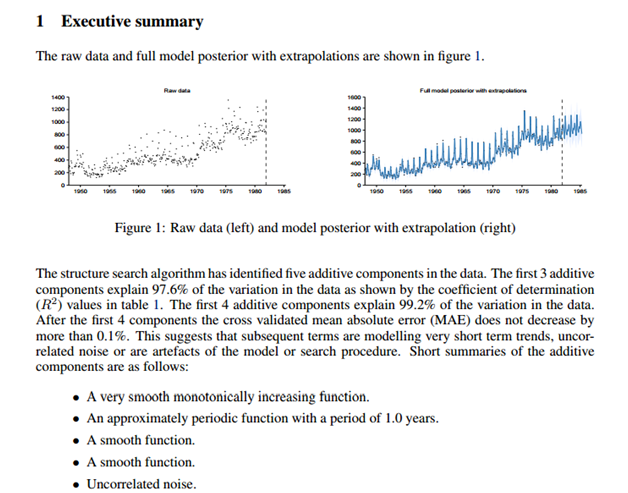
Automatic Statistician is the brainchild of Zoubin Ghahramani and his research team at the Department of Engineering – University of Cambridge. They set out to make a computer do what a Data Scientist is paid to do – make sense of data. Automatic Statistician gained recognition outside the academic circles when Google awarded the team the Google Focused Research Award. At the writing of this post, Automatic statistician is still in its early stages. Yet it has shown strong potential in applying statistical and machine learning methods on raw data, and automatically discovering trends in data; completely unsupervised.
Below is the screenshot of the automatic analysis and report by Automatic Statistician, when fed the raw data of unemployment figures
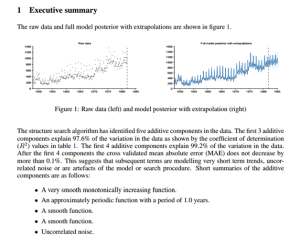
http://www.automaticstatistician.com/abcdoutput/11-unemployment.pdf
There are scores of interesting examples such as these. Machine Learning has been gaining momentum over the past decade. To repeat Ken Jennings’ sentiment: I, for one, welcome our new computer overlords.
Conclusion
Technological innovation has been reshaping the labor market for a long time now. One can date it back to the industrial revolution. For all the buzz the phrase “Big Data” has created in the recent past, I believe the advancement in AI, Robotics and Machine Learning, applied to big data is one such wave – one that will change the way we are used to do things. Many jobs from today will not exist in the near future, and many jobs in the near future are completely unknown right now. Phone operators didn’t exist for most of 18th century and neither did rocket scientists until the early 20th. Web-developers and computer network analysts didn’t exist for most of the 20th century. Big Data, AI and Machine Learning will lead to jobs that we just cannot imagine at this time.
Sure, this disruptive technology is going to negatively impact the labor market, but there is more to gain. Technology is a net job-creator. However, to mitigate the short term negative impact, a strong role from both the government and private sector is prescribed by policy experts and economists.
Computers in business are not just about making machines do the drudgery that we do not want to do. Today’s computers are much smarter – they can simulate thinking and reasoning that was previously thought of as a purely human endeavor. Today’s computers help us strategize, perform market analysis, build modes, and explore new opportunities. Tomorrow’s thinking machines will not just be helping us, but modeling these themselves, in an unsupervised way.

 Welcome to a world where digital reigns supreme. Remember when the Internet was more of a ‘push’ network? Today, it underpins how most people and businesses conduct transactions – providing peer-to-peer connections where every single interaction can be tracked.
Welcome to a world where digital reigns supreme. Remember when the Internet was more of a ‘push’ network? Today, it underpins how most people and businesses conduct transactions – providing peer-to-peer connections where every single interaction can be tracked.